Here are a few more touched-up video frame grabs from our highly photogenic study subjects, juvenile Chinook salmon in the Chena River.




Here are a few more touched-up video frame grabs from our highly photogenic study subjects, juvenile Chinook salmon in the Chena River.
Many of our model tests will depend on video footage of feeding fish, from which we digitize the 3-D coordinates of attempted prey capture maneuvers to compare against behaviors predicted by the model.
We use a stereo camera setup to get two views of everything the fish does, and digitize it in VidSync like this.
After 33 minutes of digitizing behavior for that particular fish (so far), we can calculate a cloud of points (in green) representing the positions of potential prey, relative to the fish, when the fish detected them:
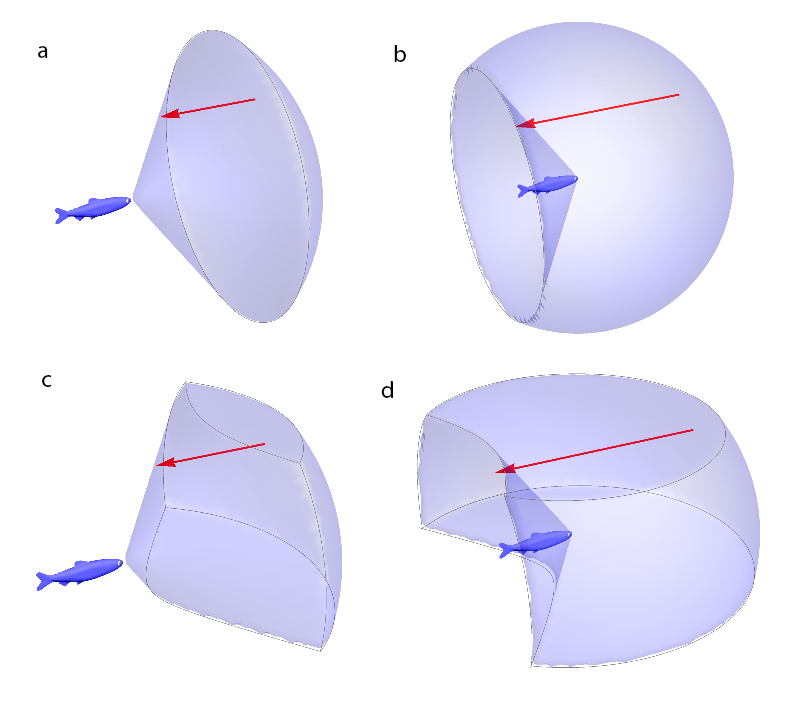
We’ll be comparing various aspects of these reaction fields to predicted volumes that look something like this: